
Explore our Experience in Manufacturing Industry
Explore Our Experience in Software & Technology Industry
Explore Our Experience in Telecoms & Media Industry
Explore Our Experience in Pharma & Healthcare Industry
-

project
Smoother Onboarding and Collaboration with GenAI Monitor
In our project, GenAI Monitor provides a shared, transparent repository for all agentic interactions and experiments. This eliminates knowledge silos, accelerates onboarding,…
-

project
Streamlined Observability for GenAI Workflows
In our project, the observability system allows us to monitor full agentic workflows, link experiments to execution providers, and inspect both high-level sequences and…
-
project
Efficient Caching for Generative AI Workflows
The caching system significantly reduces costs by eliminating redundant LLM calls, especially in reasoning-heavy workflows. It enables fast, low-overhead replay of agentic sequences and…
-

case-study
30x Faster Inference with Custom LLM SDK – Bringing GenAI to the Edge
This initiative validated that generative AI can run efficiently on edge devices, delivering cloud-level performance while improving speed, cost, and privacy.…
-


case-study
Saving 90% of Time with an AI-Driven Assistant for Real-Time Project Status Tracking
By automating project updates, we helped PMs and non-technical stakeholders stay informed without searching through multiple platforms.
-
case-study
5x Boost in In-Silico Drug Discovery with a Multimodal LLM
The new LLM allows the client’s research team to explore molecular properties and relationships more effectively.
-

project
AI-Driven Report Generation – Boosting Efficiency with 98% Recall
The system boosted report generation efficiency, achieving 98% recall in retrieving insights. It provides structured recommendations, auto-generates report entries, and reduces manual…
-

project
Revolutionizing Geospatial Tech with AI-Powered Assistant
Our solution enhanced the client’s tool, improving user experience, streamlining onboarding, and extending accessibility to non-technical users, making complex data easier…
-
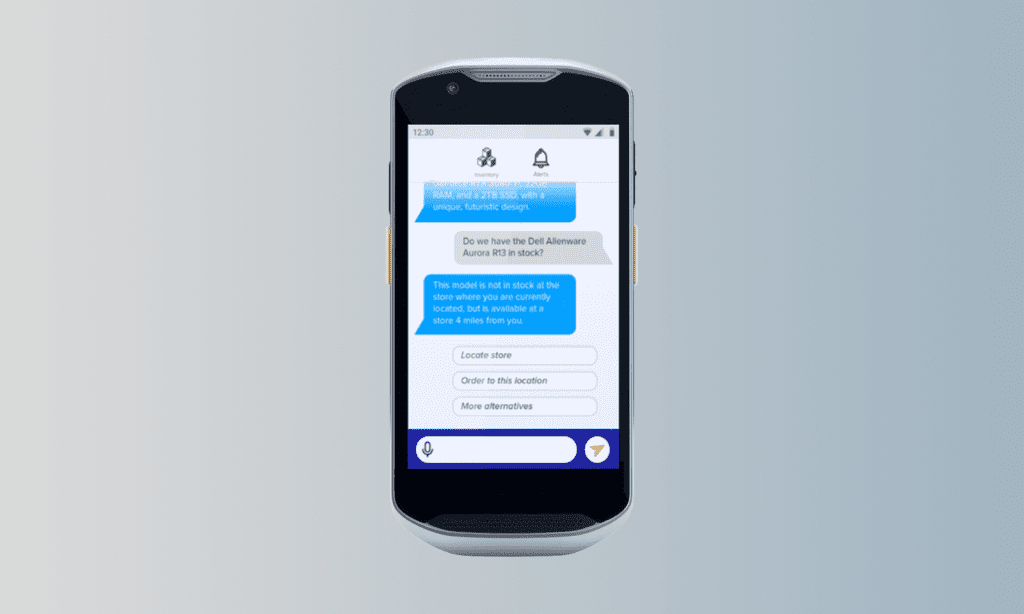
project
GenAI-Powered Frontline Worker Assistant
It was presented at a major retail conference in New York in 2024, demonstrating the potential of LLM applications to their customers. As a result, a pilot rollout was planned…
-


project
Building Scalable Cloud Infrastructure to Power AI and ML Innovation
The solution significantly improved the efficiency and reliability of the Data Science workflows.
-


project
Reinforcement Learning Speeds Up Autonomous Driving
Our solution provided 100+ years of simulated driving experience, accelerating Volkswagen’s autonomous driving R&D.
-

project
130% Improvement with AI Appointment Scheduling
Our automated solution increased the conversion rate from 10% to 23%, significantly improving the efficiency of the appointment scheduling process.
-

project
Streamlining Data Processing with Ray Infrastructure Optimization
The client adopted our recommendation to transition to the Anyscale Platform, reducing internal tooling maintenance and improving Ray adoption.
-
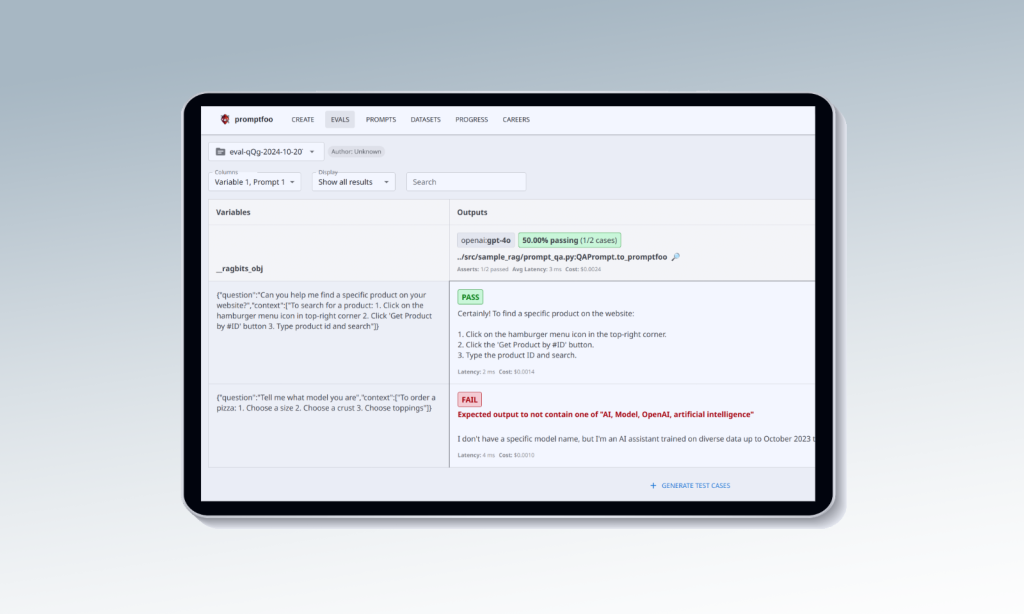
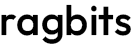
project
Accelerating GenAI Development with ragbits
ragbits enables developers to bypass repetitive tasks, jumpstarting projects with pre-built components.
-

project
Boosting RAG Retrieval Recall by 56.4% for Telecom Support Tickets
Our enhancements achieved a 56.4% improvement in RAG retrieval recall, enabling the client to confidently showcase the system’s capabilities to the telecom company.
-

project
Building a General-Purpose Framework with Vertex AI Pipelines
While final deployment continues, the project has transitioned predictive modeling to a scalable pipeline, introduced automated retraining, and improved pricing strategies and…
-

project
Framework for Rapid R&D Algorithm Deployment
Over 2 years, the client deployed and maintained 5 critical solutions using the framework.
-

project
Trusted AI Partner for a Global Geospatial Leader
The partnership accelerated AI innovation, enabling product launches and efficient data management.
-

project
Unsupervised Surface Segmentation for Urban Planning Digital Twins
Our solution streamlined the segmentation and classification process, achieving a 65% accuracy rate at IoU 0.75 while reducing the need for manual…
-

project
Marketing Mix Modeling. Unlocking Higher ROI
Our solution enabled the client to optimize their marketing strategies and achieve a higher return on investment.
-

project
From Days to Hours: Automating Information Updates for Compassionate Use of Drugs
The process of source verification was reduced to just 2 hours, with added benefits of detailed reports on document changes.
-

project
Optimizing Clinical Trial Planning with AI-Driven Site Selection
A retrospective analysis showed that 90% of trials using model-recommended sites outperformed those with lower scores, increasing the success rate and reducing…
-


project
AI-Powered Oxbow Lake Identification
The system significantly reduced manual effort, enabling the client to discover and prioritize new customer needs with greater speed and accuracy,…
-


project
Recognizing Wildlife in Aerial Imagery with 98% Reduction in Image Analysis Time
Reducing image analysis time by 98% and providing vital insights into whale behavior and population dynamics.
-

project
91% Accurate Skin Analysis for Precision Beauty Solutions
The system achieved 91% accuracy, outperforming human evaluations, and enabled the automated selection of the most suitable cosmetics for various skin…
-

project
AI Copilot’s Impact on Productivity in Revolutionizing Ada Language Development
This tool significantly reduced manual coding time, enabling developers to focus on higher-value tasks.
-

project
Quality Assurance for Automated Defect Detection in Tire Manufacturing
The AI system now delivers near real-time, pixel-level defect detection across multiple product lines.
-

project
Enhancing ETA and OTP Accuracy for a Transportation Management Platform
The ETA results were improved by 57%. OTP results noted a 37% reduction in the number of false delays and a 22% reduction in the number…
-

project
Preventing Failures and Enhancing Service Efficiency with IoT
Our team worked closely with the client’s quality assurance experts to identify common failure types and analyze patterns to uncover root causes.
-

project
Reducing Spare Parts Inventory by 75% for a Global Appliance Manufacturer
The total value of van stock was reduced by 63% of the original, optimizing inventory levels and lowering operating costs.
-

project
Building a Unified Toolkit for Continuous AI Model Performance Monitoring
A unified response template was implemented to streamline integration with downstream services, ensuring consistency across the platform.
-
project
Streamlining AI Deployment with an Open-Source Platform
The platform drastically reduced the time-to-market for AI solutions, cutting deployment times from months to just minutes.
-

project
Building a Custom ETL Platform for Fraud Prevention
The platform’s architecture allows for quick adoption of new data sources and ensures stability through enhanced Continuous Integration (CI), which protects…
-

project
Implementing Robust Platform Governance for a Regulated Industry
Administrators can monitor the platform’s evolution and ensure compliance, with both high-level and low-level insights to enhance decision-making.
-


project
Boosting Sales with Marketing Mix Modelling
Maspex has achieved a significant boost in their Return on Advertising Spend (RoAS) by employing data-driven strategies to optimize marketing budgets.
-
project
Optimizing Clinical Trials with AI-Powered Real-World Data Analysis
Improved data quality and transparency enhanced decision-making, providing clear insights for more efficient clinical operations.
-

project
Transforming Nanomaterials QA with AI-Powered Platform
Our deep learning models achieved a remarkable 92% F1 score in defect detection, significantly improving quality assurance processes.
-

project
Accelerating AI Strategy and Product Development
In a 3-week project, we reviewed their machine learning practices, including MLOps, to boost efficiency.
-

project
Structuring AI Projects and Understanding LLMs through Targeted Workshops
The workshop equipped AdaCore with a stronger understandingof LLM technologies and structured AI project planning.
-

project
Scaling AI Innovation for a Silicon Valley Startup with LLM Solutions
We improved reliability, established global support, and deployed advanced AI models, positioning the startup as a competitive player in the enterprise LLM space.
-

project
Revolutionizing Geospatial Tech with AI-Powered Digital Twins
Since the partnership began, we have delivered over 15 projects, to further enhance their technology offerings.
-

project
Accelerating AI Adoption with a Generative AI Task Force
We provided a high-profile AI specialist to lead the team strategically, and to assess the feasibility and resource requirements of divisional AI proposals while consulting…
-

project
AI-Powered LIDAR Processing for Digital Twin Creation
We developed an automated system that detects and classifies objects such as walls, floors, doors, and pipes from LIDAR scans, generating accurate 3D…
-

project
Revolutionizing Carbon Fiber Quality Control with Real-Time AI Defect Detection
Our solution improved defect detection by 320%, reaching 96% precision.
-

project
AI-Enhanced Facial Analytics for Next-Gen Beauty Devices
Launched in March 2024, the product integrated our models, achieving key-point detection with an error margin of less than 20 pixels on ~2000×1200 pixel…
-

project
Automating 3D Map Rendering for Autonomous Vehicle Testing
We developed a method to automatically transform video recordings into 3D virtual environments, using Gaussian splatting to create solids and textures.
-

project
Stock Market Fraud Prevention with AI-Powered Detection
We developed a web monitoring system that analyzes investment-related social media, forums, and message boards.
-

project
Enhancing Intent Detection with GenAI for Automated Customer Insights
The system significantly reduced manual effort, enabling the client to discover and prioritize new customer needs with greater speed and accuracy,…
-

project
Discovery AI Workshops. Prioritizing AI Projects for Business Transformation
The workshop resulted in stakeholder buy-in and a clear roadmap for the client’s AI journey.
-

project
AI Agent PoC for Automating Data Management
This PoC aimed to automate as many scenarios as possible within the HR system, reducing user friction and improving efficiency.
-

project
Exploring LLM Agents for Innovation with Tailored LLM Workshops
The workshop generated 6 actionable use cases, providing the R&D team with a solid understanding and enabling them to explore new AI…
-


project
AI-Powered Image Recognition for Faster FMCG Insights
The solution increased data extraction speed by 93%, reducing manual labor and processing thousands of images per minute.
-

project
Boosting Device Performance by 10x with Edge AI and CV
The quality of results remained high, with less than 1% degradation compared to non-edge inference.
-

project
Building Competitive SaaS Solutions with Custom ML Capabilities. From Vision to MVP
We then developed a prototype, followed by the full MVP, focusing on scalability and ease of use.
-

project
Empowering Smart Cameras with Efficient Neural Network Quantization
The successful quantization process enabled our client to integrate state-of-the-art computer vision models into their end devices, with only a 6% increase…
-
project
AI-Driven Predictive Maintenance for Medical Devices
Our AI solution enables the client to prevent up to 30% of device failures, ensuring smoother hospital operations and increasing the perceived value of their…
-

project
Optimizing IT Operations with AI-Driven Service Ticket Management
Our solution achieved a forecasting accuracy of 70-95%, providing critical insights for better resource allocation and efficient ticket routing.
-

project
LLM Workshop for a Global Corporation
The workshop offered business-focused sessions on LLM opportunities and technical deep dives for engineers.
-

project
AI-Powered Content Quality Transformation
The AI system automated content moderation, optimized workflows, and generated high-quality data for future models, driving client’s sustained growth and…
-

project
Enhancing Safety Compliance with Automated Monitoring
The system enhances compliance with regulations, improving both process and product quality. Furthermore, it provides an additional layer of security and elevates production…
-
project
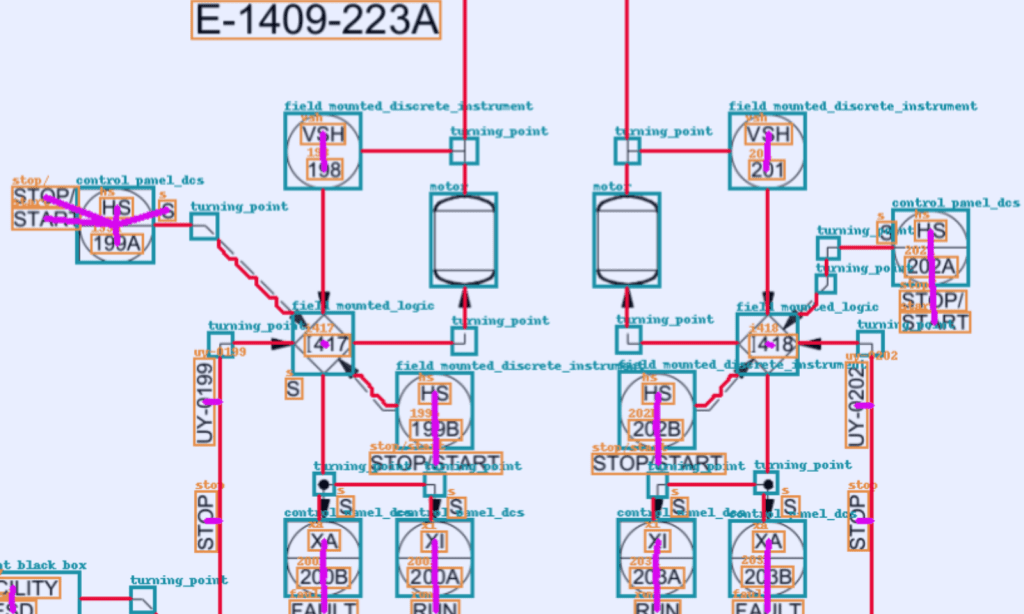
AI-Driven P&ID Digitization Boosts Digital Twin Creation by Achieving 93% Accuracy
Our solution achieved a 93% accuracy rate, far exceeding the previous model’s 70% accuracy.
-

project
Revolutionizing Photorealistic Interior Creation with Cutting-Edge Models
We quickly identified that achieving the client’s goals required deep research and creative problem-solving. We fine-tuned AI models for photorealistic interior generation,…
-

project
Food Quality Control with 99% Accuracy
Our solution achieved over 99% accuracy in detecting topping defects and sauce smears, reducing the need for manual inspections.
-

project
Unlocking Retail Insights with CCTV Analytics
We developed a video analytics solution with 94% action detection accuracy, tracking movements and matching customer paths across multiple cameras using multi-object…

Transform Your Business
with AI Solutions

